sparkSQL和hive是什么关系?在过去,hive用于构建数据仓库,因此对hive管理的数据查询有很大的需求。Hive,shark,sparlSQL都可以查询hive的数据,使用hive查询Hbase数据很慢,虚拟机本身速度很慢,Hive的使用也很重要,不能随便写。同样的查询方式,写的方法不一样,算法和时间也会不一样。
1、数据中心是什么?其系统结构和工作原理是怎样的呢?
数据中心是场所、工具、流程等的有机结合。其中企业的业务系统和数据资源被集中、集成、共享和分析。从应用层面看,包括基于数据仓库的业务系统和分析系统;从数据层面,包括运营数据和分析数据,以及数据和数据集成/整合流程;从基础设施来看,包括服务器、网络、存储和整体IT运维服务。数据中心的建设目标是:1 .完成公司总部和省公司两级数据中心,逐步实现数据和业务系统的集中化;2.建立企业数据仓库,提供丰富的数据分析和展现功能;3.实现数据的唯一性和共享性;4.建立统一的安全体系,确保数据和业务系统的访问安全;5.结合数据中心建设,完善数据交换系统,实现两个数据中心之间的级联;6.实现网络、硬件、存储设备、数据、业务系统和管理流程、IT采购流程、数据交换流程的统一和集中;7.统一的信息管理模式和统一的技术架构可以快速实施和部署各种IT系统,提高管理能力。
2、…系统和Hadoop等方面阐释大数据处理技术的基本原理?
1。文件系统:大数据处理涉及处理大量的数据文件,因此需要一个高效的文件系统来管理和存储这些文件。传统的文件系统在处理大数据时存在一些性能瓶颈,需要使用分布式文件系统来解决这个问题。分布式文件系统将数据和元数据存储在多个计算节点中,提高了文件系统的读写性能和可扩展性。2.编程模型:大数据处理需要使用适合大规模数据处理的编程模型。
在MapReduce模型中,用户只需要编写map和Reduce两个函数,系统会负责将数据划分成多个块,在多个计算节点上并行执行map和reduce操作,最后将结果合并。3.分布式存储系统:大数据处理的一个关键问题是如何管理和存储海量数据。传统的存储系统无法满足大数据处理的需求,因此有必要使用分布式存储系统。分布式存储系统将数据存储在多个计算节点中,通过数据分片和冗余备份提高数据的可靠性和可访问性。
3、Hive数据倾斜与数据膨胀小记
难得的周末。整理了一个星期的工作,发现最近一直被数据倾斜问题折腾。大家冷静下来总结一下,所谓大雁留痕。其实这个问题以前也遇到过,只是当时处理的数据量不大,这个问题可以用另一种方式规避。现在,TB级别的数据已经无法回避,这是一个惨痛的教训。把遇到的场景总结成以下三类。看具体场景,可以细分为以下几个问题。具体原理这里就不描述了。mapreduce的几个进程相当于合并器阶段,在维度表、小表(记录数在10000以下)的连接中经常出现map端的部分聚合。
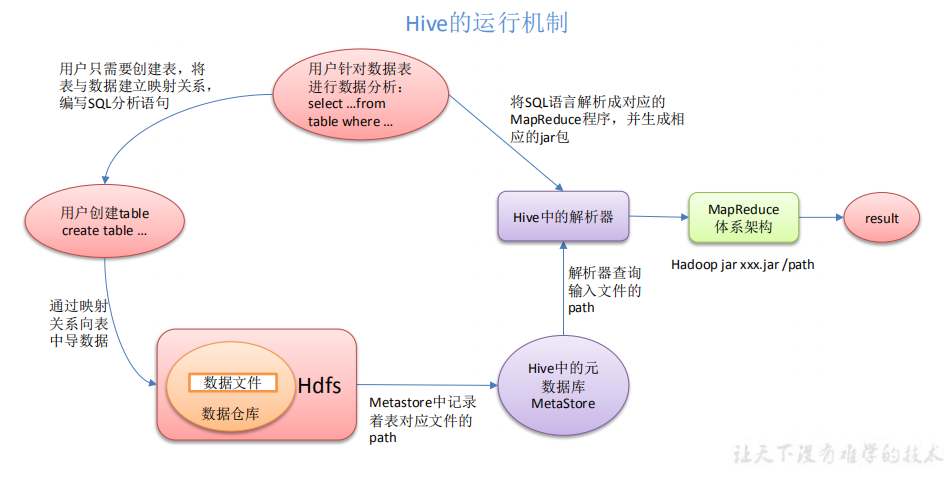
4、hadoop分布式计算中,使用Hive查询Hbase数据慢的问题
虚拟机本身速度很慢,hive的使用也很重要。不能随便写,随便写。同样的查询方式,写的方法不一样,算法和时间也会不一样。首先,hadoop引擎只有在节点规模上去了或者配置了硬件的情况下才能转起来。配置很低。一看就知道是科技项目还是小作坊。你的要求很不合理。这种配置没有优化的余地。另一方面,HIVE原则上只是一个基本的SQL转义。换句话说,当你的云计算规模上去了,HIVE优化的本质是让你优化SQL,而不是HIVE有多强。
5、sparkSQL和hive到底什么关系
历史上hive是用来搭建数据仓库的,所以对hive管理的数据查询有很大的需求。Hive,shark,sparlSQL都可以查询hive的数据,Shark是一个sql解析器和优化器,它使用hive,并修改executor使其运行在spark上。SparkSQL使用了自己的语法解析器、优化器和执行器,同时sparkSQL还扩展了接口,不仅支持hive数据的查询,还可以查询各种数据源的数据。